High Availability Clustering Solution
This solution provides a high-end solution for Bacula. If you are not experienced with these technologies, it can represent important training costs. Your needs should drive your decisions.
Using spare hardware, Bacula can be integrated with standard OpenSource Linux clustering solutions such as Heartbeat or Pacemaker from http://www.linux-ha.org
In the event of a failure, resource managers like Pacemaker or Heartbeat will automatically initiate recovery and make sure your application is available from one of the remaining machines in the cluster. Pacemaker is the new version of Heartbeat, it permits handling very complex cluster setups. With Bacula, this level of complexity is not needed so we advise you to run in a simple Primary/Slave situation, the rest of the document will refer to Heartbeat as the resource manager.
The data replication of the PostgreSQL server can be done with DRBD (Data Block Device Replication) tools from LINBIT. (http://linbit.com)
Proposed Architecture
A large site will need to run multiple Storage Daemons per Director (SD1 and SD2 in the schema), and you will probably need a dedicated PostgreSQL Catalog server per Director (SGBD on the schema).
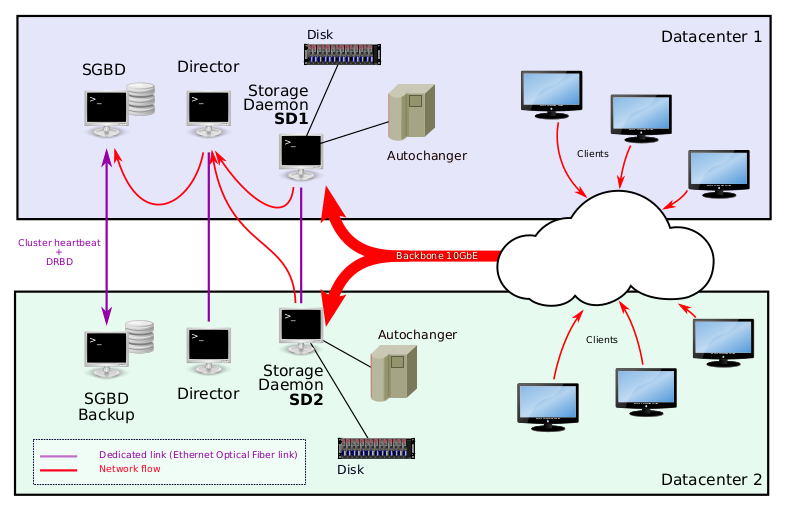
Using Bacula in a multiple data center environment
All servers should have :
RAID hardware with WriteBack capabilities
Multiple Ethernet links aggregated with failover detection using bonding kernel module, these links should be connected to different and independent network equipment
Hot plug and redundant power supply.
In this architecture, each server that is used for your Bacula installation should be protected by second one located in the other data center. Each couple of cluster nodes should have a dedicated direct Ethernet fiber optic link and may implement a STONITH mechanism. If your Storage Daemons has a single point of failure (because your disks are not mirrored between data centers for example, or you have an Autochanger directly connected), you won’t necessarily need to protect them at the same level, and some spare hardware should be sufficient.
Cluster Resources
The role of a resource agent is to abstract the service it provides and present a consistent view to the cluster, which allows the cluster to be agnostic about the resources it manages. The cluster doesn’t need to understand how the resource works because it relies on the resource agent to do the right thing when given a start, stop or monitor command.
Typically resource agents come in the form of shell scripts, however they can be written using any technology (such as C, Python or Perl) that the author is comfortable with. With Bacula, the following default resources will be used in the resource manager tool:
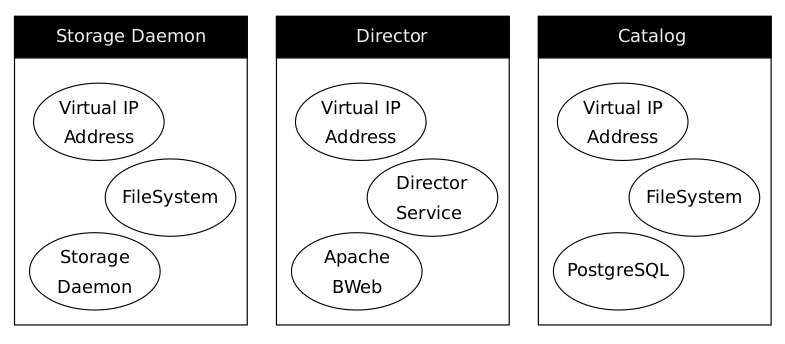
Pacemaker/Heartbeat service definition
Virtual IP Addresses
Bacula Director service
Bacula Storage services
Backup storage filesystems
PostgreSQL catalog service
PostgreSQL data and configuration filesystem
When using cluster techniques, a very common way to ensure that you can move or restart a service elsewhere on your internal network without having to reconfigure all your clients is to use virtual IP addresses for all your components. All Bacula components should have their own virtual IP address, the resource manager (Heartbeat) will ensure that only one primary node is using it at a time on your network.
Since Bacula isn’t designed to reconnect automatically when a TCP connection drops, running jobs will fail when a resource is moved from one location to another. Make sure that Bacula is stopped before moving services between hosts.
For example, the Director (host bacula-dir1) HeartBeat resource definition will look like:
bacula-dir1 IPAddr::10.0.0.2/24 bacula-dir httpd
Bacula Configuration Synchronization
In this solution, the resource manager (Heartbeat) will detect if a node or a service has a failure and will restart it at the right place, but it won’t ensure that Bacula’s configuration is synchronized between nodes. A simple and flexible way to do that is to use rsync at regular intervals on the master node and automatically after a reload command.
PostgreSQL Catalog
Protecting your SQL Catalog (PostgreSQL or MySQL) is a very large subject, there are dozens of techniques that accomplish the job.
The PostgreSQL High Availability configuration is the most complex part of this setup, to be able to restart the service on the second node after an outage, data should be replicated between nodes. This replication can use high end hardware, standard PostgreSQL replication or DRBD replication layer (RAID1 over the network, see http://linbit.com)
Clusters using HeartBeat, DRBD and PostgreSQL are very common in the OpenSource world, and it’s rather easy to find knowledge and resources about them.
Data Replication
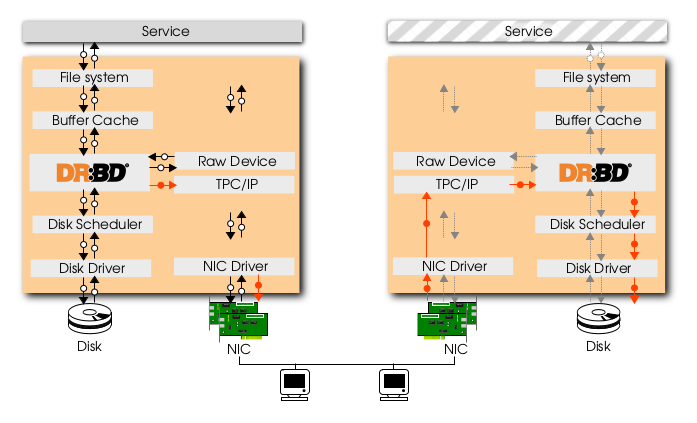
DRBD architecture
DRBD is OpenSource and has been in development for over 10 years and continues to undergo feature upgrades, it has been officially accepted into the Linux Kernel 2.6.33, it is simple, fast and flexible, it has transaction safe technology; this means that DRBD is designed to replicate data in a reliable, secure and safe method no matter how sensitive your payload is. DRBD has support options: it may be installation assistance, 24/7 support or a single support incident, LINBIT can help.
The performance cost of this block level replication is around 10/15% of the overall disk throughput, but it has the major advantage to be very safe and simple during standby/takeover operations, it’s almost impossible to loose your data with bad sequence of commands. Streaming replication using PostgreSQL is faster, but requires taking careful steps before reactivating the replication and being protected again.
Since DRBD is well integrated with HeartBeat (LINBIT is now the official maintainer of HeartBeat resource manager), once volumes are initialized and synchronized, the HeartBeat resource definition on the bacula-sql1 host will look like:
bacula-sql1 IPAddr::10.0.0.1/24 drbddisk::postgres \
Filesystem::/dev/drbd0::/pgdata::ext3 postgresql
Go back to the High Availability chapter.
Go back to the main Bacula Infrastructure Recovery page.