High Availability
Bacula has several different ways to perform High Availability, some of them are easy to implement but not fully automatic, others are more complex, but can reduce the downtime to a couple of seconds.
High Availability solutions are described for GNU/Linux Redhat systems, database High Availability solutions are described for PostgreSQL.
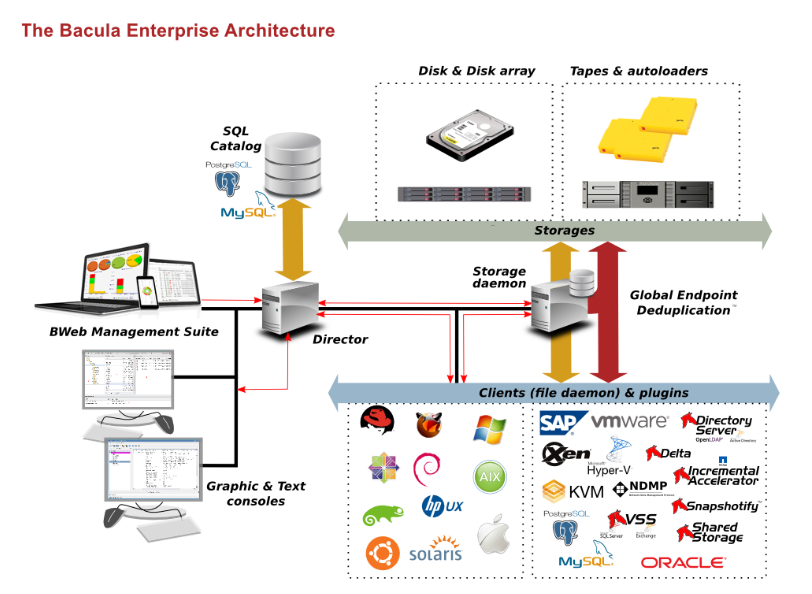
Bacula Components
Solution Comparison
Max. downtime |
Solution |
Notes |
|---|---|---|
\(<\) 5 mins |
High Availability cluster and database block level replication |
Need to be experienced with clustering technologies such as HACMP, HeartBeat- /Pacemaker, etc. |
\(<\) 1-3 hours |
Spare hardware and database replication |
Need a clear procedure to restore Bacula and use PostgreSQL internal replication. |
\(<\) 12 hours |
Spare hardware and database restore |
Need a clear procedure to restore Bacula and you can restore PostgreSQL catalog from the last backup. |
If you loose your Catalog server, all records about jobs that ran after your previous Catalog backup will be lost. Keeping trace of emails and Bootstrap files is sufficient to restore files, but it’s not very convenient. To avoid this problem, you can use the PostgreSQL Continuous Archiving option and do binary Catalog backups instead of the default SQL dump procedure. See https://www.postgresql.org/docs/current/continuous-archiving.html for more information.
Read more:
Go back to the main Bacula Infrastructure Recovery page.