High Availability: Architecture
CommunityEnterpriseHigh Availability (HA) can be achieved at different levels and through different techniques with Bacula. Thanks to the flexibility of the Bacula architecture, it is not necessary to rely on a single technique, nor to apply the same approach to all components.
In the following sections, we separate each component and analyze possible architectures that can provide HA. The final choice depends on the specific requirements of the environment as well as and operational practices of the administration team responsible for maintaining it.
We begin with a couple of examples of complete HA setups.
Foundation Example Architecture
We start with a concrete example of a full architecture suitable for a large Bacula Enterprise deployment. This example serves to introduce the core concepts that will be explored in greater detail in subsequent sections. The central idea is to replicate, at the block-level, the essential data for the Catalog, the Director, and the Storage Daemons.
Large Bacula Enterprise deployments, especially those operating across multiple data centers, typically require multiple Storage Daemons (SDs) per Director (e.g., SD1 and SD2 in the architecture) as well as a dedicated PostgreSQL Catalog server for each Director. When designing for high availability, it is often preferable to isolate the Catalog on its own highly resilient database node (shown as SGBD in the diagrams) to ensure predictable performance and failover behavior.
In this example architecture, block-level replication is used to synchronize both the Director configuration and its Catalog across geographically separated data centers. The Directors form a cluster managed by Pacemaker and replicated using DRBD. This setup ensures only one Director instance is active at any given time, while the passive node is continuously synchronized. The active Director then orchestrates backup and copy operations across the two Storage Daemons.
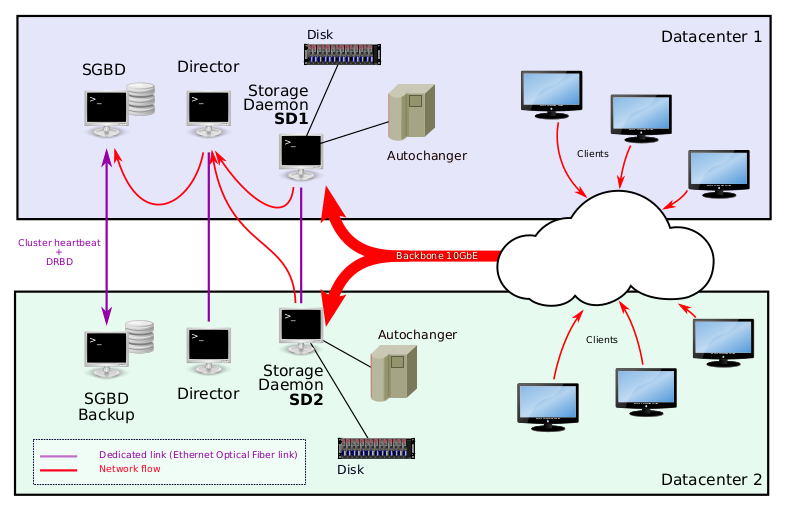
Using Bacula in a multiple data center environment
Server Requirements
All servers participating in this architecture should meet the following baseline requirements to ensure high availability and resilience:
Hardware RAID with WriteBack caching: Ensures I/O consistency and protects against disk failures while maintaining high write throughput.
Redundant, aggregated network connectivity: Multiple Ethernet links should be bonded with failover detection (Linux bonding module) and connected to independent network switches or fabrics to eliminate single points of network failure.
Redundant, hot-plug power supplies: Guarantees continued operation in the event of power supply failure or power-path interruption.
These requirements apply to all nodes forming the HA cluster, including Directors, PostgreSQL servers, and, depending on the design, Storage Daemons.
Node Pairing and Failover Domains
In this architecture, each critical Bacula component (Director and Catalog) is paired with a redundant node located in the opposite data center, forming a two-node failover domain. Each node pair should be interconnected by a dedicated, high-bandwidth, low-latency fiber link to support DRBD synchronization and cluster heartbeats.
To avoid split-brain events and ensure deterministic failover, a STONITH (Shoot-The-Other-Node-In-The-Head) mechanism is strongly recommended. Pacemaker uses STONITH to guarantee that only one Director or Catalog instance is active at any moment, which is essential for the correctness of both Bacula Catalog and the DRBD block device.
Not all components necessarily require identical levels of protection. If your Storage Daemons rely on hardware that cannot be mirrored across data centers, such as an autochanger or non-replicated storage disks, it may be acceptable to use cold-spare hardware instead of a fully clustered SD pair. The key principle is that the Bacula Director and Catalog must not become single points of failure, while SD redundancy can be adapted to your storage model and operational constraints.
Throughout this document, this architecture is referred to as Pacemaker over DRBD.
Cross-Datacenter Directors for Full HA
When implementing high availability across two data centers, it is often desirable to maintain two independent Directors, one in each data center, while ensuring that each Director is replicated and available in the remote location. This approach allows either site to assume the primary role in the event of a local outage.
In such scenarios, configuration replication can be delegated to the storage layer (e.g., DRBD, distributed filesystems, external NFS resource replicated by other means). This simplifies the Director failover process and reduces the operational burden at the backup application layer.
The overall architecture is remains similar to the previously described cluster but introduces cross-references between Directors and Storage Daemons to provide redundancy and load distribution. This design is illustrated below and also introduces the internal components that are discussed in subsequent sections.
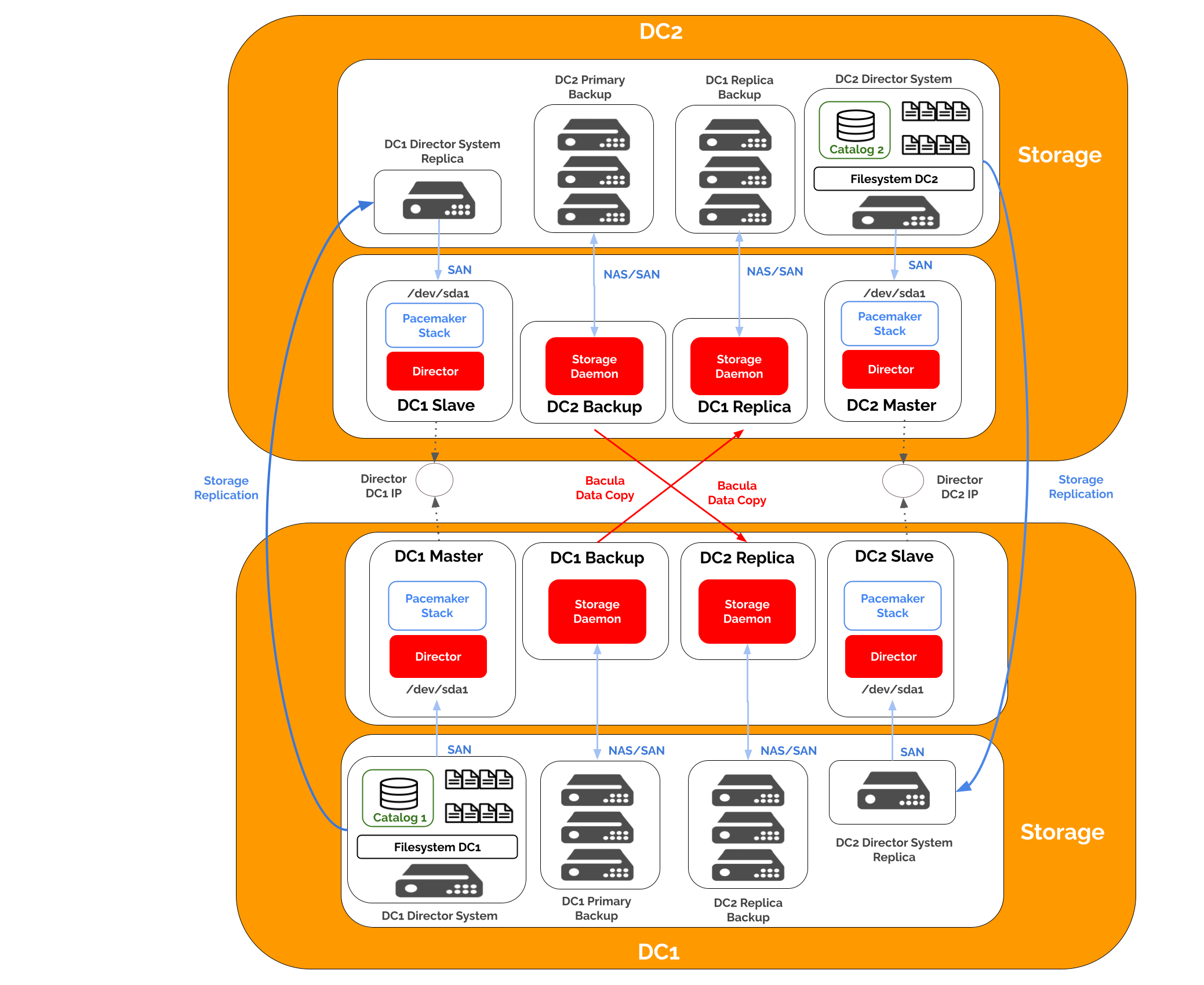
In this multi-data center architecture, each Director communicates primarily with its local Storage Daemon to minimize latency and maximize performance. Backup data is written locally first, ensuring fast job completion and efficient resource usage.
Bacula Copy Jobs or Migration Jobs are then used to replicate backup data asynchronously to the remote Storage Daemon in the opposite data center. This approach provides off-site redundancy without introducing latency into the primary backup workflow. As a result, each data center retains a local copy of its data while ensuring that a secondary copy is available at the remote location to meet disaster recovery and compliance requirements.
See also
Previous articles:
Next articles:
Go back to: High Availability.