High Availability: Director
CommunityEnterpriseIn this article, we analyze the architecturalHigh Availability (HA) options for the Bacula Director component, which consists of three main elements:
The Bacula Director service
The Catalog (a PostgreSQL database)
The Bacula configuration (a directory containing text files)
High Availability can be established by treating the three of them together or by separating them. The different alternatives are discussed below.
Pacemaker over DRBD
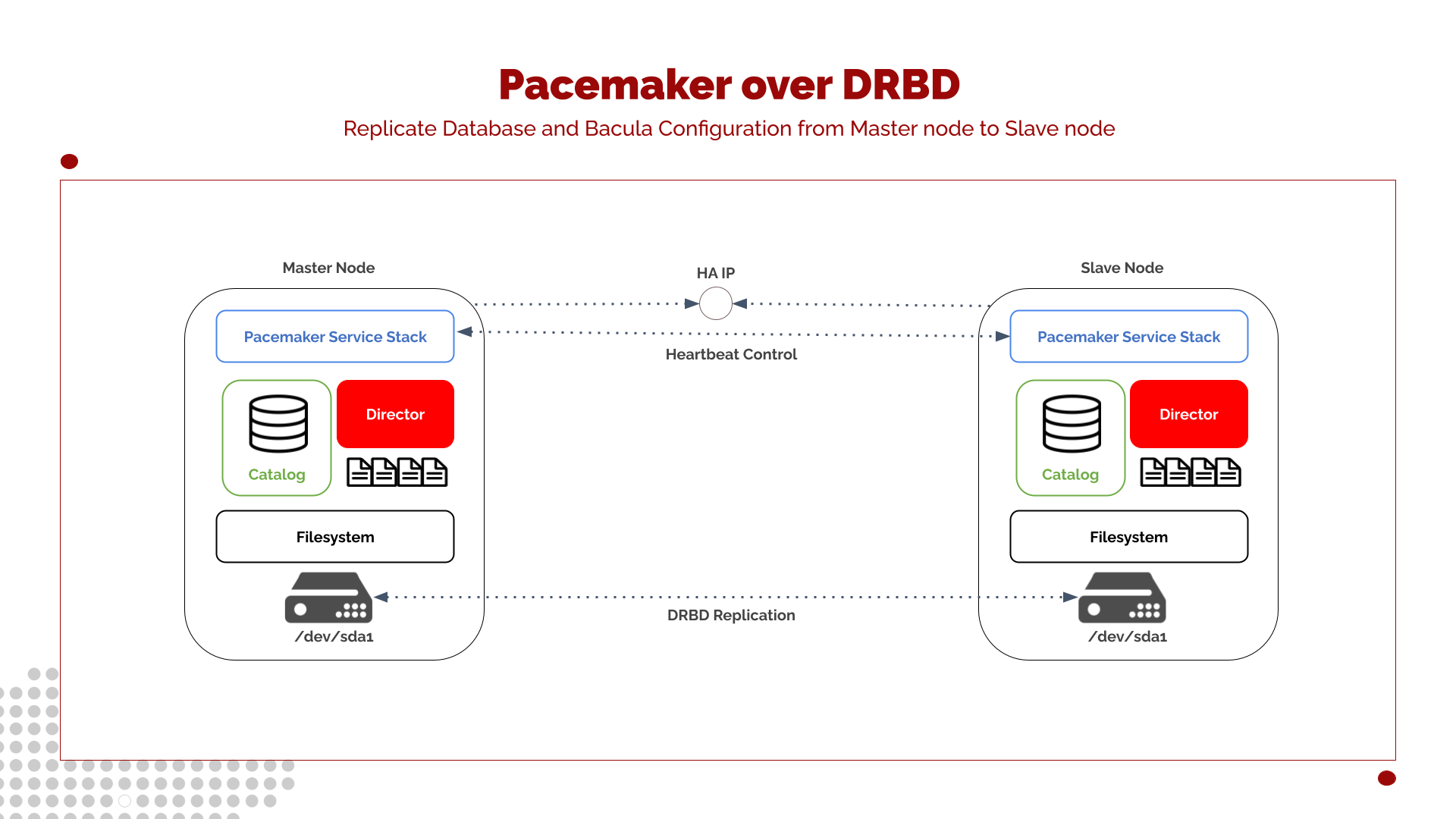
This architecture represents a two-node cluster in which both the Bacula Director and the Catalog are deployed as highly available services. Each node contains its own local storage device, which hosts the operating system as well as the Bacula configuration files and the PostgreSQL Catalog data. This model corresponds to the foundational architecture described earlier in High Availability: Architecture.
Pacemaker manages the entire service stack associated with the Bacula Director to guarantee that only one node is active at any given time. The active node exposes a High Availability (floating) IP address, ensuring that external systems, such as the Storage Daemons, File Daemons, or administrative tools, interact with Bacula transparently, regardless of which physical node currently holds the active role.
The typical Pacemaker-managed service stack includes:
Mounting the replicated filesystem (DRBD-backed device)
Starting the PostgreSQL Catalog service
Starting the Bacula Director service
Bringing up the High Availability IP
This sequence ensures that every dependency is correctly initialized and that the Director always runs against a consistent, synchronized copy of its Catalog and configuration.
Because each node uses its own local disk for the configuration and database, a replication mechanism is required to guarantee data consistency during failover. This architecture uses DRBD (Distributed Replicated Block Device) to provide block-level mirroring between the two nodes.
DRBD ensures that:
Any writes performed on the active node (database modifications, configuration updates, job status changes, etc.)
Are synchronously or asynchronously replicated to the passive node
Maintaining data integrity and enabling seamless failover
This approach abstracts replication at the block device layer, ensuring that Bacula and PostgreSQL operate on a standard filesystem without requiring application-level modifications.
Deploying this architecture requires working knowledge of Pacemaker, Corosync, and DRBD. These technologies are mature, widely adopted in the industry, and known for their stability. However, as with any clustered system, operational procedures must be in place — especially to prevent and resolve split-brain scenarios.
To avoid data divergence when communication between nodes is disrupted, a STONITH (Shoot-The-Other-Node-In-The-Head) mechanism is essential. It allows Pacemaker to forcibly fence a misbehaving node, ensuring that DRBD and PostgreSQL never operate in multiple-writer mode.
Extensive documentation is available online for both Pacemaker and DRBD, and administrators are encouraged to familiarize themselves with fencing, quorum considerations, and DRBD recovery workflows to operate the cluster safely and confidently.
The following architectures build upon the concepts introduced in this proposal.
Pacemaker with Shared Network Storage
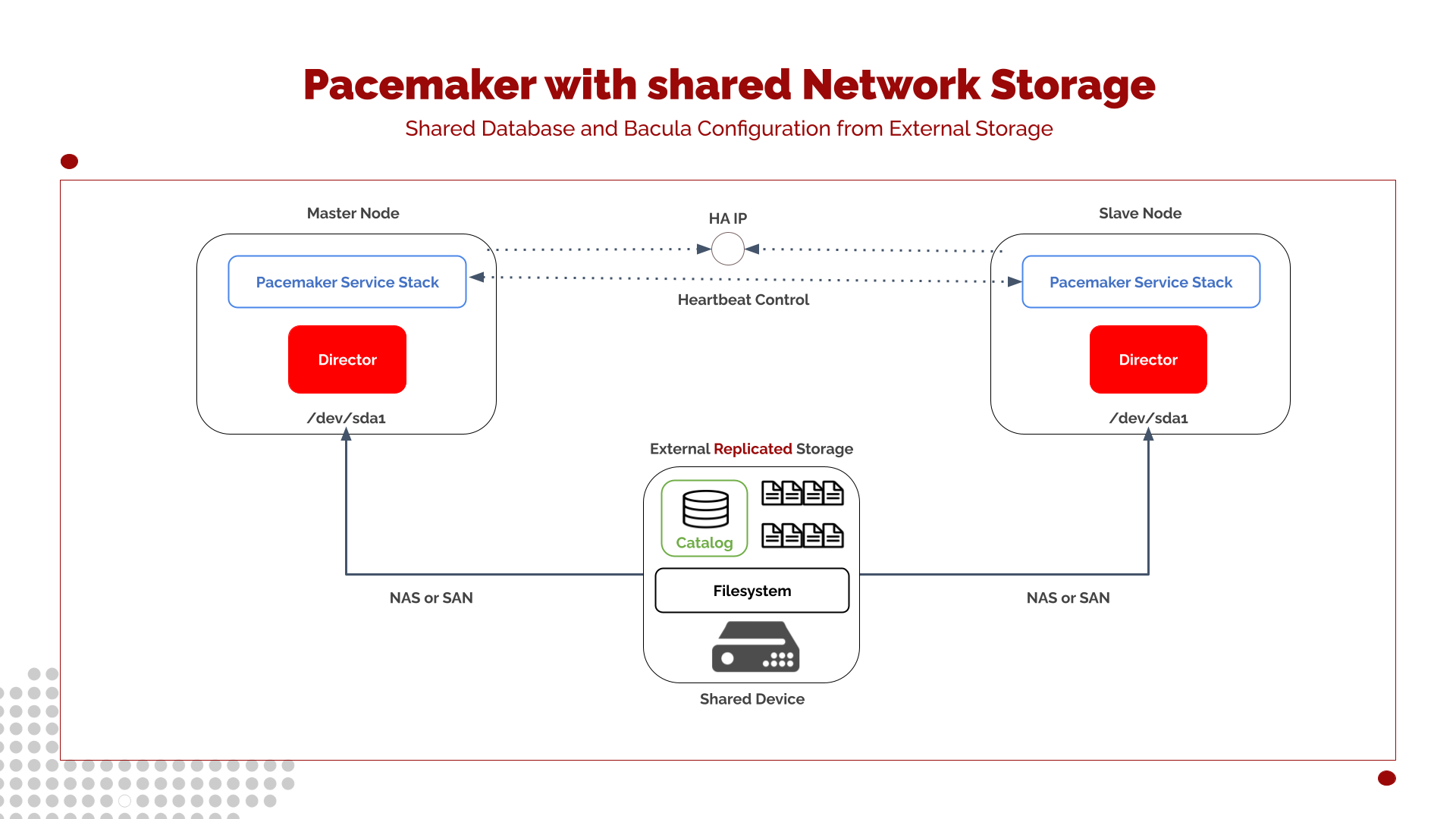
This architecture follows the same high-availability principles described in the previous section. It consists of two nodes capable of providing the Bacula Director service, coordinated through a Pacemaker/Corosync cluster stack, ensuring that only one Director instance is active at any given time.
The key difference here is the relocation of the storage that holds:
PostgreSQL Catalog data, and
Bacula Director configuration files
Instead of storing these on local disks replicated via DRBD, the architecture uses an external shared storage system provided by an enterprise-grade SAN or NAS platform. Both cluster nodes access the same storage device over standardized block- or file-level protocols (e.g., iSCSI, Fibre Channel, NFS, or SMB).
This approach allows the Director and Catalog services to always access the same data volume, regardless of which node is currently active, without requiring block-level replication between nodes.
Benefits and Simplifications
By removing the DRBD layer, this variant:
Reduces operational complexity
Eliminates DRBD-specific synchronization and split-brain handling
Simplifies failover logic (storage is already shared)
Decreases the number of components administrators must maintain
For environments with existing enterprise storage infrastructure, this can lead to a much simpler and more maintainable HA deployment.
External Storage Requirements and Considerations
Because the shared storage becomes a critical dependency, it must be highly reliable and fault-tolerant. Otherwise, it becomes a single point of failure - undermining the entire high-availability architecture.
To mitigate this risk, the shared storage platform should provide:
Built-in redundancy (controllers, disks, power, network paths)
Snapshots or continuous data protection
Replication to a secondary location (another physical site or cloud)
Backup policies independent of the Bacula Director configuration
Multipath I/O (MPIO) from each node to ensure network resilience
If the shared storage lacks adequate redundancy or replication, you should not rely solely on this architecture. In that case, protecting the storage via off-site replication or frequent snapshots is strongly recommended to avoid data loss in disaster scenarios.
External Catalog and Distributed Filesystem
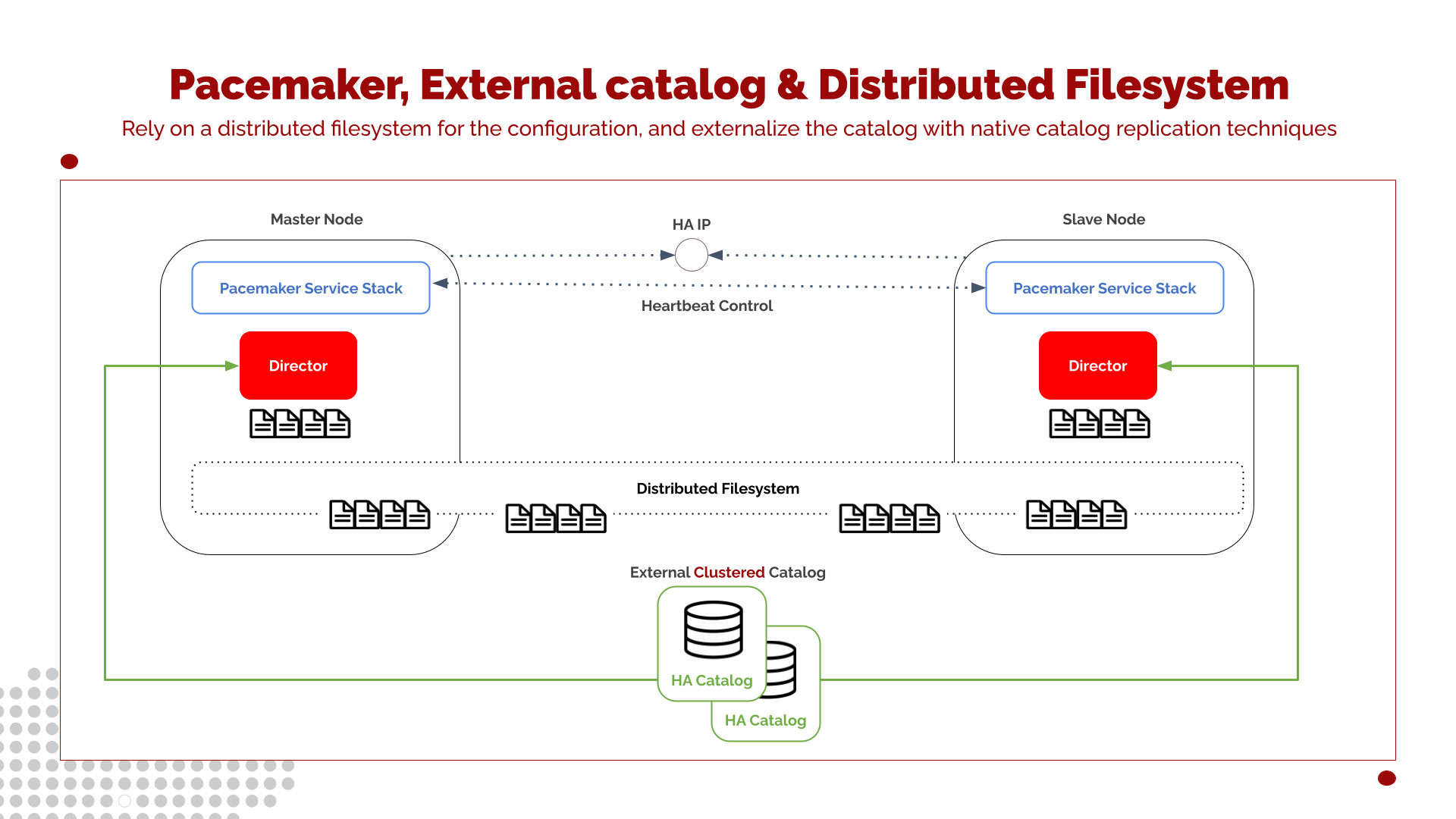
This architecture follows the principles of the previously described shared-storage model. However, in this variant, the Catalog component is fully decoupled from the Director cluster and provided with its own independent HA layer. As a result, the Catalog becomes entirely transparent to Bacula, regardless of which Director node is active. Techniques for implementing this database-level high availability are detailed in the HA Catalog section.
High-Availability Catalog Separation
PostgreSQL Catalog can be isolated into a dedicated HA subsystem—such as:
PostgreSQL native synchronous replication
Patroni with etcd/Consul
Pacemaker-managed PostgreSQL clusters
Cloud-native HA database services
By doing that, the Director cluster no longer needs to manage or replicate Catalog storage directly. This separation provides clearer operational boundaries and allows each subsystem (Director vs. Catalog) to be scaled or secured independently.
Distributed, Geo-Replicated Filesystem for Configuration
The second key component of this architecture is the use of a distributed, fault-tolerant, and geo-replicated filesystem for storing the Bacula Director configuration files. Common technologies include CephFS, GlusterFS, Lustre, or other enterprise-grade distributed filesystems.
This shared filesystem provides the following benefits:
Automatic configuration consistency
Both Director nodes always see the exact same configuration state without requiring block-level replication or manual synchronization.
Distributed filesystems can maintain multiple replicas across data centers, ensuring configuration availability even in site-level failures. Since the configuration is always up-to-date across nodes, the passive node can become active immediately when Pacemaker triggers a failover.
Another advantage is that storage ownership switching is no longer required. Unlike DRBD or shared SAN models, the filesystem is naturally accessible by both nodes simultaneously, simplifying the service stack.
In this design, the Director service managed by Pacemaker simply mounts or accesses the distributed filesystem and starts the Director process. There is no need to promote or demote storage devices, and failover workflow becomes significantly lighter.
Further discussion on how to cluster Bacula Configuration is available in the HA: Bacula Configuration Synchronization section.
Using a Version Sontrol System
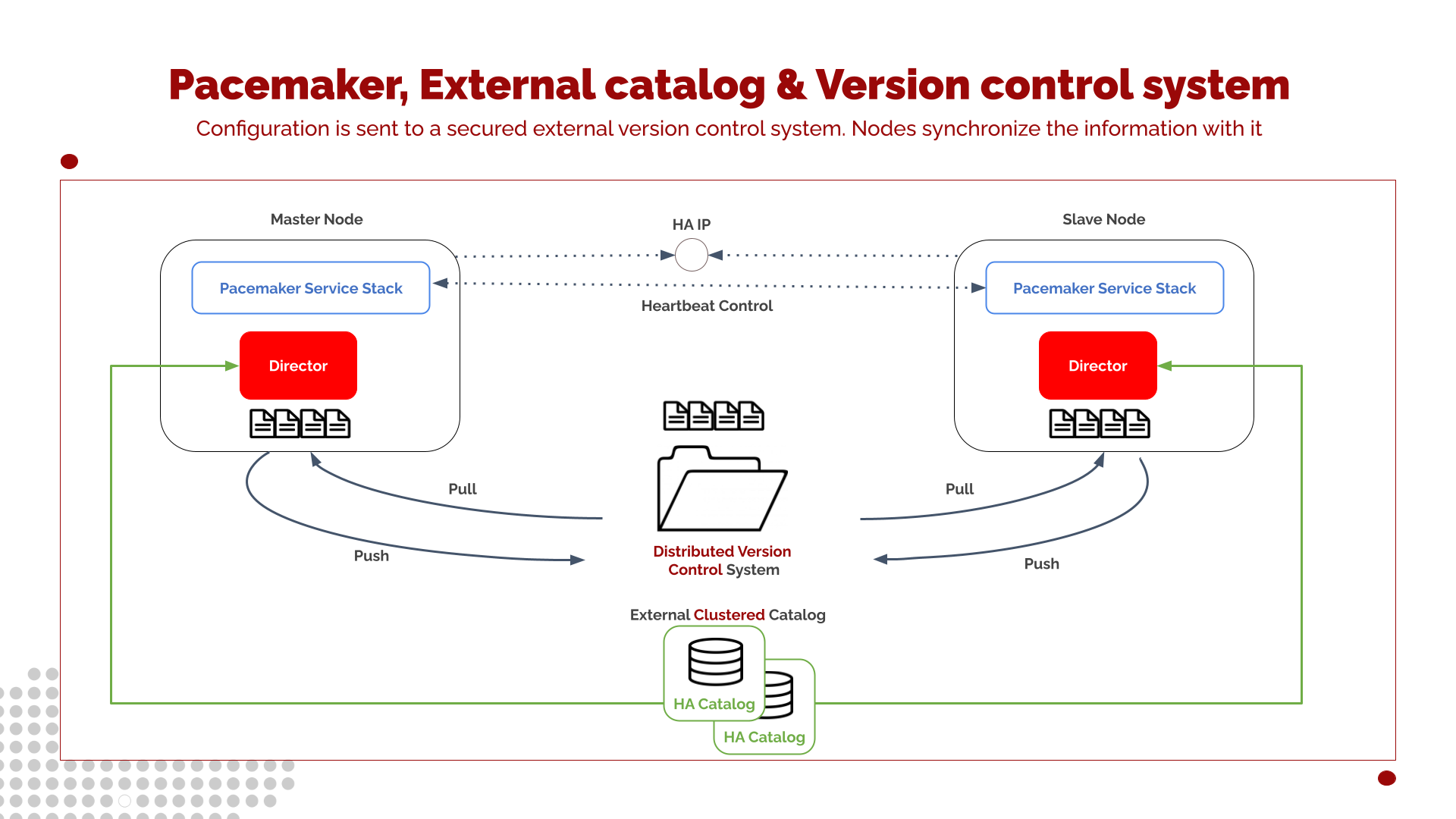
Building on the previous architecture—where the Catalog is fully externalized and protected by its own High Availability layer, this variant replaces the distributed filesystem used for Bacula configuration with a Distributed Version Control System (DVCS) such as Git.
Instead of sharing a live, replicated filesystem, configuration synchronization relies on version-controlled updates managed by each Director node.
In this model:
Each node pushes configuration changes to a central version-control repository whenever updates occur (e.g., job changes, new clients, schedule adjustments).
When a node transitions from standby to active in the Pacemaker cluster, it performs a pull operation to retrieve the latest configuration state before the Director service starts.
The DVCS ensures that only validated and committed configuration changes are applied, reducing the risk of unintended drift.
Advantages include:
Built-in Version History
Every change is automatically recorded with full revision history, enabling:
Easy rollback
Auditing of configuration changes
Improved change-management practices
Avoids Replicated Storage Complexity
Unlike distributed filesystems or DRBD-based block replication:
No storage-layer failover logic is required
No shared or geo-replicated filesystem is needed
Configuration updates are treated as application-level data, not storage-level blocks
Simplified Operational Model
Nodes remain fully independent at the filesystem level. Only the configuration directory is synchronized through Git, and the workflow is entirely transparent to Bacula.
DVCS Considerations
To ensure reliability and consistency:
The version control repository should reside on highly available infrastructure (mirrored Git servers, cloud-hosted DVCS, etc.).
Configuration pushes should be automated and validated to avoid conflicts. If BWeb is used, integration scripting will be necessary.
Nodes must pull the latest configuration state before promoting the Director service during failover.
This model combines strong configuration governance with a lighter, more flexible approach to data distribution—ideal for environments already using GitOps or centralized configuration management practices.
Hypervisor-based HA
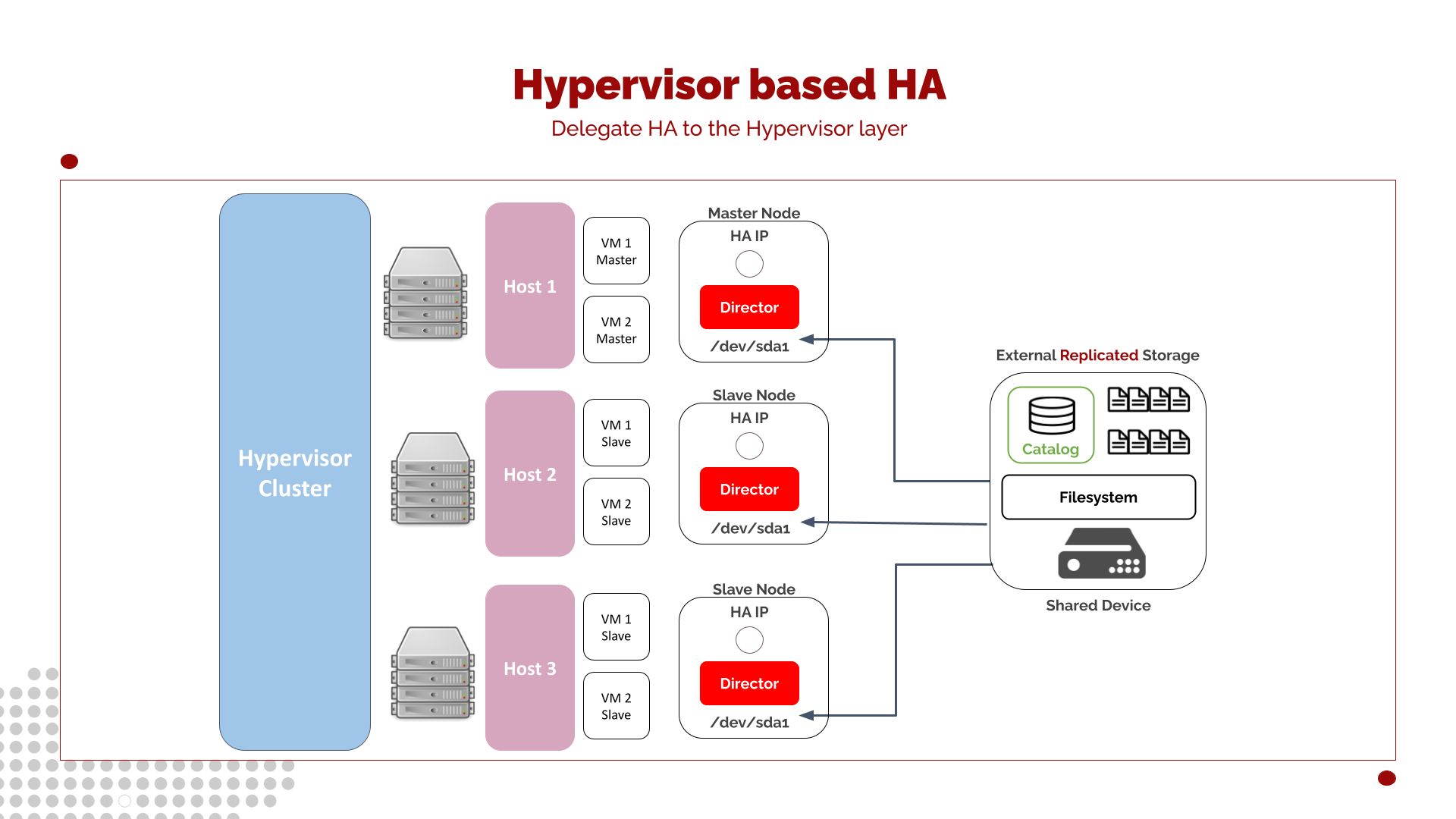
Virtualization technologies and Infrastructure-as-a-Service (IaaS) platforms are now widely adopted across medium and large organizations. These environments frequently host mission-critical applications that already rely on hypervisor-level High Availability (HA) to ensure continuous service delivery.
In this context, the Bacula Director can be treated like any other virtualized service. Modern hypervisors - such as VMware vSphere, Proxmox VE, Microsoft Hyper-V, KVM-based platforms, and cloud-native infrastructures - offer built-in HA capabilities that automatically restart or migrate virtual machines when hardware or host failures occur.
Leveraging this layer of HA often provides a simpler, more resource-efficient, and operationally mature solution compared to implementing cluster-based HA using Pacemaker or DRBD.
In this model, both Director availability and network failover are delegated entirely to the hypervisor. When a failure is detected in the underlying host, the virtualization platform automatically fails over the Director virtual machine to another healthy host, ensuring minimal downtime and no need for complex clustering logic inside the Bacula application stack.
Storage Considerations in Virtualized HA
While CPU and memory failover are managed by the hypervisor, storage remains a critical element that must be consistent across all nodes in the environment. The Director configuration and the Catalog database must be accessible to whichever virtual machine instance becomes active after failover.
To meet this requirement, any of the previously discussed storage techniques may be used, such as DRBD, distributed filesystems, or configuration synchronization systems. However, in virtualization or IaaS contexts, the simplest and most recommended approach is to rely on external shared storage (e.g., SAN, NAS, cloud block storage) that is accessible simultaneously by all hypervisor nodes, with its own built-in redundancy, replication, and snapshot capabilities.
Using external shared storage aligns naturally with hypervisor HA design: VMs become mobile across hypervisor hosts, but the storage backing them remains consistent and centrally managed.
This approach is often the most practical and operationally efficient strategy for organizations already invested in enterprise virtualization or cloud infrastructure platforms.
Hypervisor-based HA with External Catalog
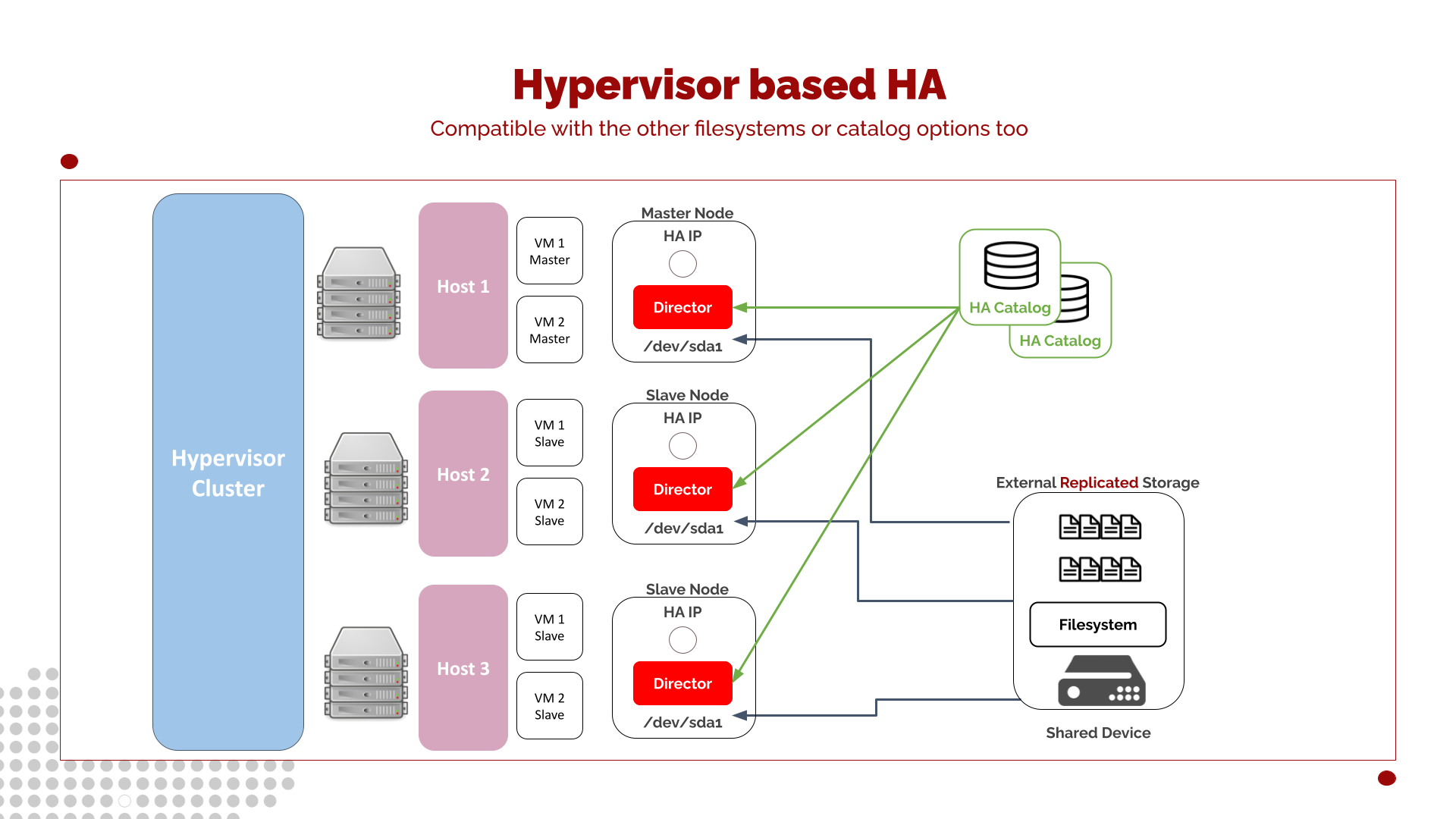
Building on the hypervisor-based architecture presented earlier, this variant introduces an additional level of resilience by delegating the Catalog to an independent High Availability subsystem. While the Bacula Director continues to benefit from hypervisor-managed failover, the Catalog is moved outside the virtual machine and protected by a dedicated HA database layer.
In this design, the Director virtual machine relies on:
Hypervisor High Availability for compute and networking continuity, and
External shared storage for Director configuration and runtime data.
However, instead of storing the Catalog on the same shared storage device as the Director, the Catalog is housed in an autonomous, highly available PostgreSQL cluster, for example, using Patroni, Pacemaker-managed PostgreSQL, cloud-managed HA databases, or synchronous streaming replication. This approach allows the Catalog to maintain its own redundancy, failover rules, and recovery logic independently of the Director.
Advantages of this hybrid model include:
Reduced Director VM Complexity: The Director VM is lightweight, stateless in terms of Catalog data, and can be restarted or migrated by the hypervisor without storage-level replication concerns.
Independent Catalog Continuity: The Catalog remains available even during Director VM failover or maintenance events. Database failover occurs according to its own HA policy, unaffected by hypervisor operations.
Improved Scalability and Resilience: Each layer, compute (hypervisor), configuration storage (shared storage), and database (HA PostgreSQL), can be optimized, scaled, or maintained independently, reducing cross-layer fault domains.
Alignment with Modern Architectural Practices: Many organizations today centralize databases separately, using purpose-built HA technologies rather than embedding the database inside virtual-machine-level failover patterns.
The shared storage device is still required for Director configuration and operational state. However, because the Catalog is externalized, the shared storage no longer needs to provide database-grade consistency, replication, or failover. This reduces the storage system’s criticality somewhat and allows the Catalog layer to use highly specialized tools designed specifically for database availability and data integrity.
To summarize, this variant combines:
Hypervisor-level HA for the Director.
Shared external storage for Director configuration.
A fully independent, highly available external Catalog service.
The result is a balanced architecture that benefits from the simplicity of hypervisor failover while leveraging robust database-centric HA mechanisms, offering strong resilience with fewer moving parts than traditional application-level clustering.
See also
Previous articles:
Next articles:
Go back to: High Availability.