High Availability: Catalog
CommunityEnterpriseProtecting your SQL Catalog (PostgreSQL or MySQL) is a broad subject, with dozens of techniques to accomplish the job. In this section, we focus on PostgreSQL, which is the recommended database engine for running Bacula.
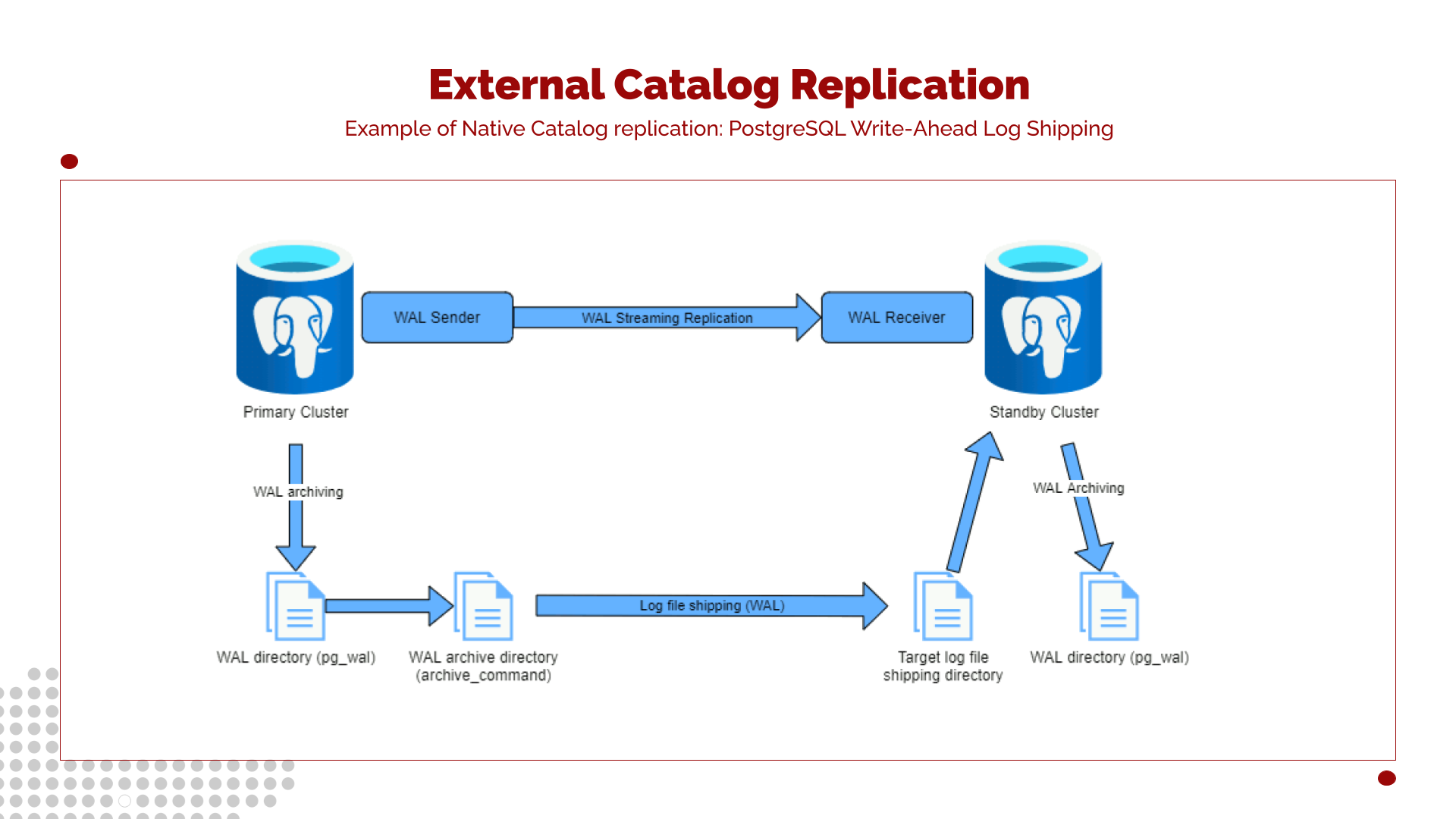
The PostgreSQL high availability configuration is the most complex part of this setup. To allow the database service to restart on a secondary node after an outage, data must be replicated between nodes. This replication can rely on high-end hardware solutions, standard PostgreSQL replication (logical replication), or a physical replication layer, including block-level replication using tools such as DRBD - RAID1 over the network (see http://linbit.com) ), among others.
When native replication is used to provide the Catalog service transparently to the Director and any other layer of Bacula, the recommended technique is to use Write-Ahead Log shipping. In this approach, replicas connect to the WAL stream of the primary node and continuously apply changes. However, note that having support from database management experts is recommended in this situation.
PostgreSQL Replication Techniques
Below is a summary of the main PostgreSQL replication techniques. Some of them (such as Shared Disk and Block Device Replication) have already been covered in previous points as general techniques for High Availability at Bacula level.
File System (Block Device) Replication
A modified version of shared hardware functionality is file system replication, where all changes are mirrored to a file system residing on another computer. The critical requirement is that write operations are applied to the standby in the same order as on the primary to ensure consistency. DRBD is a widely used file system replication solution for Linux.
Write-Ahead Log Shipping
Warm and hot standby servers can be kept current by reading Write-Ahead Log (WAL) records. If the primary server fails, the standby contains almost all of the primary’s data and can be promoted quickly. WAL shipping can be configured in synchronous or asynchronous mode and can only be done for the entire database server.
Standby servers can be implemented using file-based log shipping, streaming replication, or a combination of both.
Logical Replication
Logical replication allows a database server to send a stream of data modifications to another server. PostgreSQL logical replication constructs a stream of logical data modifications from the WAL, enabling replication at a per-table level. A server publishing its changes can also subscribe to changes from another server, allowing multi-directional data flow. Third-party extensions can provide similar functionality through the logical decoding interface.
Trigger-Based Primary-Standby Replication
Trigger-based replication setup typically funnels data modification queries to a designated primary server. Operating per table, the primary server sends data changes (typically) asynchronously to the standby servers. Standby servers can answer queries while the primary is running and may support local data changes or write activity. This form of replication is often used for offloading large analytical or data warehouse queries.
Slony-I is an example of trigger-based replication, supporting per-table granularity and multiple standby servers. Because updates are applied asynchronously and in batches, some data loss is possible during failover.
SQL-Based Replication Middleware
SQL-based replication middleware intercepts SQL queries and forwards them to one or more servers. Each server operates independently. Read-write queries must be sent to all servers to keep data consistent, while read-only queries can be distributed to improve scalability.
If queries are broadcast unmodified, functions like random(), CURRENT_TIMESTAMP, or
sequences can have different values on different servers. Each server operates
independently, and SQL queries are broadcast rather than actual data changes. If this is
unacceptable, the middleware or the application must determine such values from a single
source and then use those values in write queries. Transaction consistency must also be ensured,
often through two-phase commit mechanisms (PREPARE TRANSACTION and COMMIT PREPARED).
Pgpool-II and Continuent Tungsten are examples of this approach.
Asynchronous Multimaster Replication
Keeping data consistent among servers is a challenge for servers that are not regularly connected or have slow communication links, like laptops or remote servers. Using asynchronous multimaster replication, each server works independently and periodically communicates with other servers to identify conflicting transactions. Conflicts are detected and resolved either manually or through predefined rules. Bucardo is a well-known implementation of this replication model.
Synchronous Multimaster Replication
In synchronous multimaster replication, all servers can accept write requests, and modified data is transmitted from the original server to every other server before each transaction is committed. While this guarantees consistency, heavy write workloads can lead to increased locking and commit latency, leading to poor performance. Read requests can be sent to any server. Some implementations rely on shared disks to reduce communication overhead.
This model is best suited for predominantly read-heavy workloads. Its primary advantage is the
absence of a single designated primary server, therefore there is no need to partition workloads
between primary and standby servers. Because the data changes are sent from one server
to another, there is no problem with non-deterministic functions like random().
PostgreSQL does not offer this type of replication, although PostgreSQL two-phase commit
(PREPARE TRANSACTION and COMMIT PREPARED) can be implemented in application code
or middleware.
Physical Replication Approach
Clusters using HeartBeat, DRBD and PostgreSQL are very common in the OpenSource world, and it’s rather easy to find knowledge and resources about them.
Those tools can be considered have been a solid way to achieve failover at the system and storage level for many decades. They synchronize disks or monitor processes to move the database service between servers in the event of a failure and the replication is done at the physical block level.
Logical Replication Approach
As infrastructures became more distributed and dynamic - spanning containers, virtual machines, and hybrid clouds - physical replication approaches have revealed certain limitations:
Failover logic tied to low-level storage or IP resources, not the database’s logical state.
Lack of read replicas or load-balanced read scaling.
Complex maintenance and opaque failover decisions.
Limited observability and integration with cloud-native tooling.
While some of those limitations have been mitigated in traditional tools, a newer approach based on logical replication has gained popularity, so it meets modern expectations for resilience, automation, and observability. This approach, in the context of the PostgreSQL ecosystem, consists of new technologies designed for distributed coordination and self-managing clusters.
Today, one of the most standard open-source architectures for PostgreSQL high availability combines several mature technologies that compose the other recommended approach to build highly resilient environments with Bacula. They are:
PostgreSQL
etcd
Patroni
HAProxy
Keepalived
These components are described in more detail below.
PostgreSQL
At the core of the stack is PostgreSQL itself - a robust, ACID-compliant database engine widely trusted in production environments. It supports streaming replication, enabling real-time read replicas and rapid promotion in case of a failure.
etcd: Distributed Consensus Store
etcd is a lightweight, fault-tolerant, distributed key-value store developed as part of the Kubernetes ecosystem. It implements the Raft consensus algorithm, providing:
A single source of truth for cluster state and leader information
Health checks and time-based leases for automatic failover
Consistent coordination between nodes
In this architecture, etcd serves as the control plane for the PostgreSQL cluster, storing health and leadership information for all nodes.
Official project page: https://etcd.io/
Patroni: PostgreSQL Cluster Manager
Patroni is the intelligent control layer sitting above PostgreSQL. It automates:
Cluster initialization and replication setup
Leader election (via etcd)
Health monitoring
Automated failover and recovery
Re-promotion of failed primaries using
pg_rewind
Patroni is the core technology of this HA stack and it transforms standalone PostgreSQL instances into an autonomous, self-healing cluster, with built-in REST APIs for orchestration and monitoring. It speaks directly to etcd to acquire leadership locks and to PostgreSQL to start, stop, promote, or replicate instances.
Patroni supports synchronous and asynchronous replication modes. Synchronous replication guarantees no data loss, as a client receives a success confirmation only after the data is safely on at least two nodes. It significantly reduces write throughput, however, the primary node must wait for a replica.
Asynchronous replication acknowledges writes immediately and propagates changes in the background, offering higher performance at the cost of potential data loss during failover. This mode offers maximum write throughput and it is the default behavior of Patroni.
The appropriate mode depends on network latency, workload characteristics, and data consistency requirements.
Patroni is a very powerful and flexible tool. A thorough understanding of its configuration options and trade-offs is strongly recommended before deploying it in production environments. Refer to the official documentation at https://patroni.readthedocs.io/en/latest/
HAProxy or Virtual IP: Connection Routing Layer
HAProxy sits above the database layer and presents a single connection endpoint to client applications. It dynamically routes:
Writes to the current primary (leader)
Reads to replicas (if configured for load distribution)
This separation ensures applications remain unaware of failover events, as connections automatically move to the new leader.
More information is available at: https://www.haproxy.org/
Keepalived: Virtual IP
Keepalived is a lightweight, open-source daemon that provides high-availability and load-balancing capabilities using the Virtual Router Redundancy Protocol (VRRP). Its main purpose is to manage a floating virtual IP address (VIP) that can automatically move between servers in a cluster, ensuring continuous service availability even if one node fails.
When combined with systems like HAProxy over Patroni, Keepalived allows database or application clients to always connect through a single, stable IP endpoint, while the underlying active node can change seamlessly during failover events. This approach is simple, robust, and widely used for achieving IP-level redundancy in both on-premises and cloud environments.
More information is available at: https://www.keepalived.org/
Architecture Overview
This architecture represents an evolution of PostgreSQL high availability architecture towards a model defined by resilience, flexibility, and operational maturity. Each component (Patroni, etcd, HAProxy, keepalived and PostgreSQL) has proven reliability and is built on well-understood open-source principles. Together, they create a cohesive system capable of automatic recovery, consistent replication, and intelligent failover without sacrificing control or transparency. The design supports a wide range of deployment models, from physical servers to virtualized infrastructures, adapting naturally to both small installations and large enterprise environments.
When this stack is deployed across two geographically separated data centers, each layer can be distributed across dedicated nodes. With four instances of each component, the resulting architecture resembles the following:
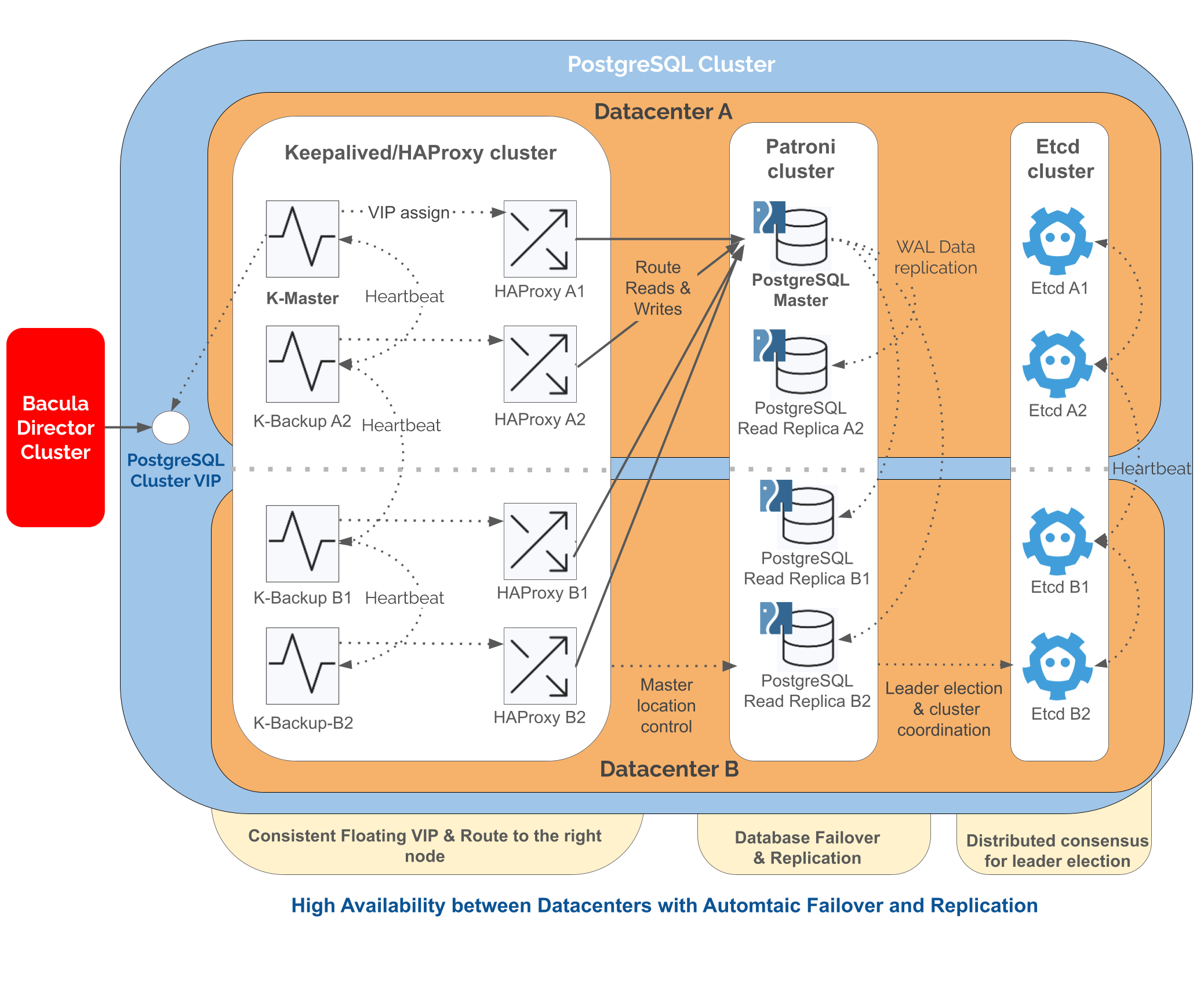
PostgreSQL HA Recommended Architecture
By integrating this stack with Bacula, organizations benefit from a robust, self-regulating PostgreSQL cluster that minimizes downtime, safeguards data integrity, and leverages technologies refined through extensive community use and real-world performance.
See also
Previous articles:
Next articles:
Go back to: High Availability.